2014 Minnesota Vikings: Game Theory and quarterback competitions
By now, you’ve probably seen the news that Christian Ponder isn’t taking too many snaps at quarterback compared to Matt Cassel and Teddy Bridgewater. In most reports, Ponder takes a back seat to Cassel and Bridgewater. Bridgewater has passed the ball a few more times, but it seems clear that Cassel is the presumed starter heading into camp.
All quarterbacks have been given impressive control at the line of scrimmage, which is nice but perhaps irrelevant to the battle at hand given the fact that the system is new for everybody.
In talking with Dusty on my podcast at the Daily Norseman, he stumbled upon an idea that I didn’t think too critically about until I listed to the podcast again: the process by which coaches assign reps for quarterbacks.
The way that we instinctively compare the distribution of snaps in the QB competition is against a simple 33-33-33 setup, where each quarterback would get a third of the snaps and it would be decided upon from there. That makes a lot of sense, and it’s pretty simple.
But “fair” doesn’t mean “balanced,” and Ponder can be given “enough” snaps to see if he can fit before determining that he deserves more snaps or isn’t starter-quality.
Dusty brought up two points that together make the case that it’s possible Christian Ponder is in a “fair” quarterback competition with the other two quarterbacks while still receiving fewer snaps. The first is that because Matt Cassel is the presumed starter, he should be given more snaps because chemistry will be very important in the season.
As a result, the other quarterbacks should get fewer snaps, but enough to evaluate them for their fit. If at some point, they demonstrate ability that exceeds the presumed starter, they’ll get more snaps.
The second point is that because Christian Ponder is a known quantity, at least relative to someone like Teddy Bridgewater, he should get fewer snaps because there’s less needed in terms of evaluation. This isn’t as important for Cassel, because as the presumed starter, evaluation isn’t a priority; chemistry is.
This is important, because people often know that both evaluation and preparation are important parts of training camp, but don’t often see them as things that trade off with each other. This is why I haven’t been as gung-ho about quarterback competitions (or competitions at other positions) as others have in the past; it’s fine and dandy that you have some idea of who the best at the position is, but what does it matter if they aren’t comfortable in the system with the players they’re supposed to play with?
That doesn’t mean competition is a bad thing, only that it trades off with other things.
The more you look at it, the more complex it gets—which is why it may be best expressed in the decision-making strategies encompassed in game theory. At the most complex level, there’s a bit of calculus involved (as it is an optimization problem), but I’ve forgotten how to do that and we can skip it anyway, because precision is not important.
First, to understand the assumptions I’m working off of you can briefly glance at the first part of a training camp notebook I put together from last year, but this graph does most of the work:

Every individual rep will provide a different amount of value in whichever function you’re looking at. For a generic player, the first rep will provide a lot of help in learning the plays and scheme, as well as developing talent.
The next rep will offer a little less, and each rep will providing a diminishing amount of learning value thereafter.
But the other function of plays on the field is that it allows a coach to see how good a player is. The first rep will tell someone basically nothing about a player for a few reasons. The first and most obvious reason is that it’s simply not that much information. How do you know that the block he missed was because he’s a bad player and not just bad luck?
The second reason is because the player doesn’t know what he’s supposed to do, because he hasn’t taken any reps yet!
So, each consecutive rep will provide more information, and getting a larger sample size of reps to work with gets more and more valuable, as will the fact that you know how the player will perform once he knows what he needs to do-as he theoretically will on Sunday.
After a point, of course, there’s only so much more information that a rep can provide. Think about seeing the 600th snap after seeing 599 previous snaps. You won’t be changing your opinion of that player because of that snap. In fact, it might take 75 more snaps before you start changing your conclusions about what you saw and 50 more after that before you confirm that changed opinion.
For quarterbacks, this can briefly be expressed as a probability for how well we can evaluate how good they are. The more reps we give a quarterback, the more certain we are of their ability. For veterans, we know a lot more than rookies; there’s a definite amount of film and history that can be applied to figure out what their talent level is. Nevertheless, a new system and terminology can be massively beneficial or detrimental, so the amount of knowledge isn’t extraordinary.
Further, with a vet we’ll know a lot of what we’ll need to know as soon as bullets fly; which tendencies remain and which ones have been eliminated. That’s invaluable information if you know what to check against. You have a history of information to grade the veteran with, and you’ll get a good idea of what you see by the end of installation.
For a rookie, you won’t know if tendencies are even there until you have a significant number of snaps. For the most part, you won’t know what you need to know even if they get all the reps.
The crux is that a rookie is going to improve a lot more with reps than a vet is. You can create a competing set of charts to model this (insert your own numbers, the concept remains the same):
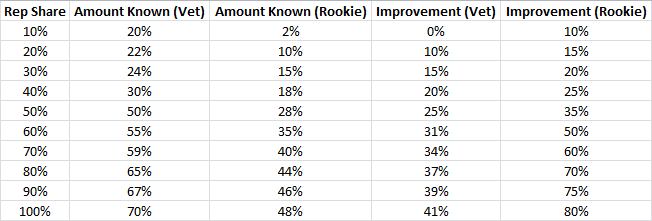
There are a lot of reasons to give the rookie reps, but you really don’t know if they’re worth it for a while. The veteran can earn reps and use them, but you’ll be chasing marginal gains. The problem with two different models of knowledge and development are pretty stark, especially in a three-quarterback race.
A better way to think about it is wins. If you set floors and ceiling for how many wins you get from a quarterback, then translate that into bands of uncertainty and improvement metrics, you’re in a good spot.
A bad quarterback is going to limit your wins (here, let’s say the win floor is three games because of the massive talent on the offense and the improving defense) and a good quarterback is going to push you to unexpected wins (the ceiling should be 10 wins if Bridgewater starts and puts in an RGIII-level performance with a few more lucky bounces and a better defense than Washington).
None of that is true if you don’t give them reps, though.
From the perspective of average wins from the percentage of reps given, you might be able to model it like such (assuming that they get reps after being named the starter after the third preseason game or so):

But that doesn’t tell you enough. We already know that Matt Cassel is a better quarterback than Christian Ponder, and that an arbitrary first-round quarterback (in this case, Teddy Bridgewater), on average is worse than an average starter (which Matt Cassel is not, but is close enough to for the purposes of this exercise).
We know this is incomplete because we know that the point of practice isn’t only to get better. It’s to know who is better. So, if we encompass uncertainty bands around the quarterbacks based on available knowledge, it looks like this:
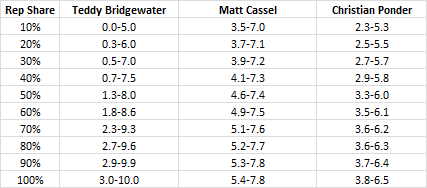
Here, you can see the uncertainty bands decrease for Bridgewater, but not by much (and yes, it looks like the total win differential increases, but the total amount of information about his available talent level decreases relative to what we can know, ie the range of possible wins compared as a percentage against possible wins is much lower). We know that his floor is three wins, which is valuable information. If Ponder or Cassel have a lower floor, then it’s a no-brainer.
We also know that we don’t know much about rookies, which is why his band is so very wide for his first year (seven games of difference). Both Matt Cassel and Christian Ponder have smaller degrees of uncertainty at the beginning and they don’t decrease by much.
Both Cassel and Ponder see the absolute differences in their floor and ceiling decrease with reps, and that’s because there’s less variability in how they can perform: they are who they are and have had a lot of snaps in the NFL to prove it. We know their floor is higher than Teddy’s because rookies wash out, but these two have not. We also know their ceiling is lower because they have shown limited talent level, while Bridgewater is definitely an unknown.
Note that the average of the floor and ceiling is not the expected win total; think of that as the median amount of wins a quarterback is going to give you (and therefore the probability curve of all possible wins is skewed in a direction like so):
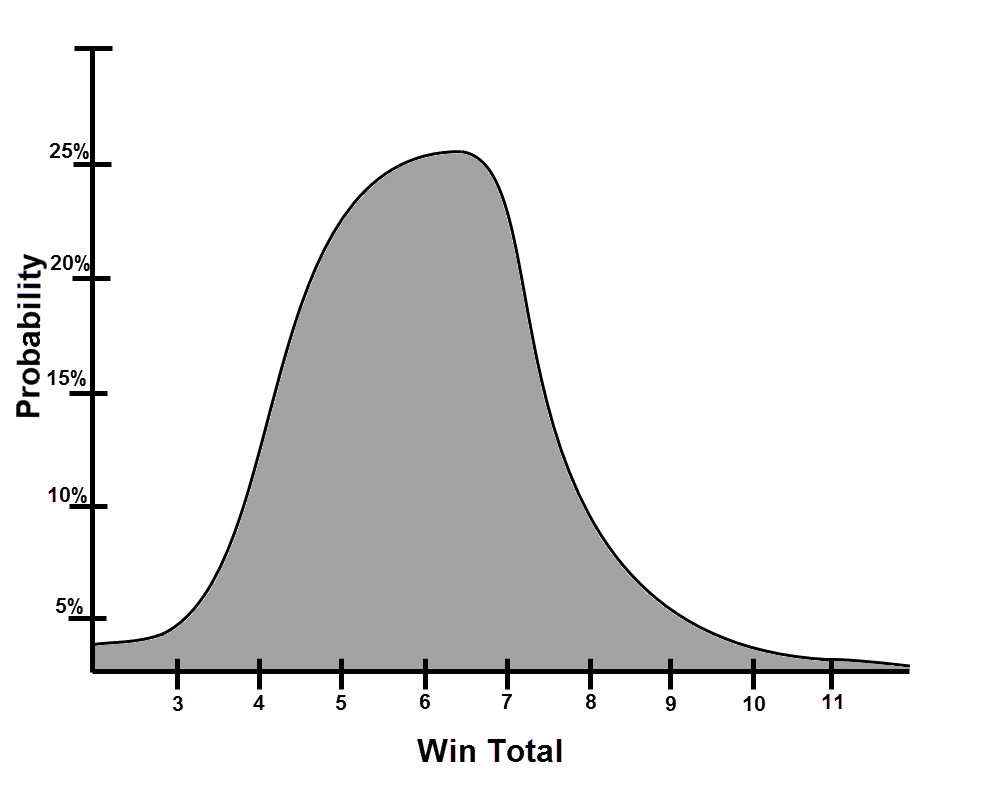
Functionally, we are 95% confident that Teddy Bridgewater will bring us between 3-10 wins, but the likeliest win total is closer to six than seven despite the fact that 6.5 is the average. Five wins are more likely than eight and so on.
Obviously all these numbers are hypothetical, but it does demonstrate the challenge of determining who gets what reps. Optimizing the reps using all of those probability curves would mean finding the spot where all three quarterbacks combine for the most wins. The biggest issue is that it’s a three-dimensional optimization problem, which requires more calculus than I remember practicing.
Roughly, assuming all of the assumptions have been correct, you can create close optimizations. With crudely similar distributions, a QB battle consisting only of Cassel and Ponder has an ideal split at about 70-30. That would give the Vikings a 16 percent chance of five wins, a 15 percent chance of six wins and a 14 percent chance of seven wins.
Between Teddy and Cassel, the optimal split is 70-30 in favor of Teddy, with a 33 percent chance of six wins, a 26 percent chance of five wins and a 21 percent chance of seven wins. Between Teddy and Ponder, the split moves to 80-20 in favor of Teddy, where there’s a 25 percent chance of five wins, a 23 percent chance of six wins and a 21 percent chance of four wins.
The distribution among all three looks to be split evenly between 70-20-10 for Teddy-Cassel-Ponder and 60-20-20. Given the assumption that veteran quarterbacks progress similarly both in terms of knowledge provided and improvement with reps, it’s not a huge surprise. The first distribution gives the Vikings a 27 percent chance of five wins, a 27 percent chance of six wins, and a 17 percent chance of four wins. With that comes a 13 percent chance of seven wins and a seven percent chance of three wins.
The second distribution gives a 29 percent chance of five wins, a 26 percent chance of six wins and a 19 percent chance of four wins.
The assumptions here are a little off and if I’m being truthful the math also assume the quarterbacks split time in the season (there’s a more complicated formula that will search for maximum wins instead of averaging them), but it functionally provides an appropriate proxy for determining how to split reps given certain functions and assumptions.
Naturally, the projected wins and distribution change based on the information you have and the assumptions you take, but the functional model for determining how to distribute reps remains the same.
Even if we assume that a veteran will be hard pressed to find wins early in the season as a starter if he doesn’t take many or any reps with the first team offense (and remember how elite veteran quarterbacks opened the lockout), it’s still likely more valuable to give the rookie more reps in general because the value of information is high; there’s a limited amount of information to be gained from Cassel and Ponder that we don’t already know and a lot of information about Bridgewater still to be discovered.
We can further complicate this by arguing that second-team reps are good at evaluation and instruction even if they’re not as good and price that fact in as well, but for now let’s keep this as simple as we can while still demonstrating the complexity of the concept.
That said, Mike Zimmer and his staff did shortcircuit a lot of this by implementing a decision time and sticking to it partway through the process, which by itself will almost always increase the win total. Nevertheless, it’s a good exercise to think about heading into an offseason.
You must be logged in to post a comment.